 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open and Reproducible Deep Research Agent for Long-Form Question Answering
Dec 15, 2025



We present an open deep research system for long-form question answering, selected as a winning system in the text-to-text track of the MMU-RAG competition at NeurIPS 2025. The system combines an open-source large language model (LLM) with an open web search API to perform iterative retrieval, reasoning, and synthesis in real-world open-domain settings. To enhance reasoning quality, we apply preference tuning based on LLM-as-a-judge feedback that evaluates multiple aspects, including clarity, insightfulness, and factuality. Our experimental results show that the proposed method consistently improves answer quality across all three aspects. Our source code is publicly available at https://github.com/efficient-deep-research/efficient-deep-research.
LEIA: Facilitating Cross-Lingual Knowledge Transfer in Language Models with Entity-based Data Augmentation
Feb 18, 2024



Adapting English-based large language models (LLMs) to other languages has become increasingly popular due to the efficiency and potential of cross-lingual transfer. However, existing language adaptation methods often overlook the benefits of cross-lingual supervision. In this study, we introduce LEIA, a language adaptation tuning method that utilizes Wikipedia entity names aligned across languages. This method involves augmenting the target language corpus with English entity names and training the model using left-to-right language modeling. We assess LEIA on diverse question answering datasets using 7B-parameter LLMs, demonstrating significant performance gains across various non-English languages. The source code is available at https://github.com/studio-ousia/leia.
Arukikata Travelogue Dataset with Geographic Entity Mention, Coreference, and Link Annotation
May 23, 2023



Geoparsing is a fundamental technique for analyzing geo-entity information in text. We focus on document-level geoparsing, which considers geographic relatedness among geo-entity mentions, and presents a Japanese travelogue dataset designed for evaluating document-level geoparsing systems. Our dataset comprises 200 travelogue documents with rich geo-entity information: 12,171 mentions, 6,339 coreference clusters, and 2,551 geo-entities linked to geo-database entries.
MIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
Jul 02, 2022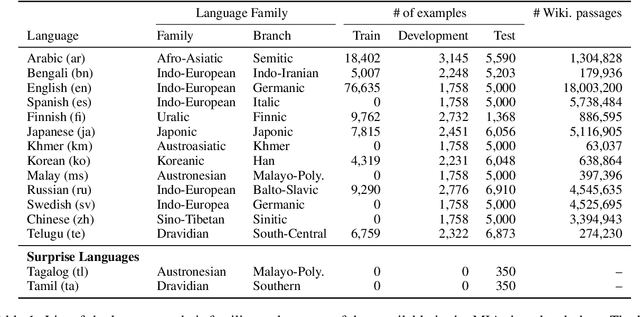
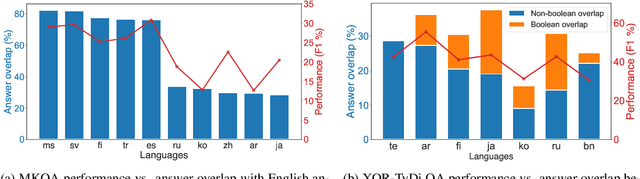
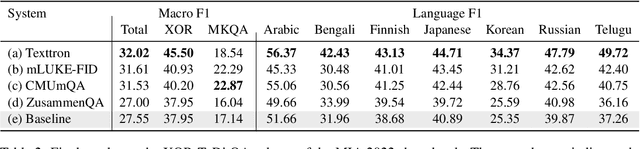
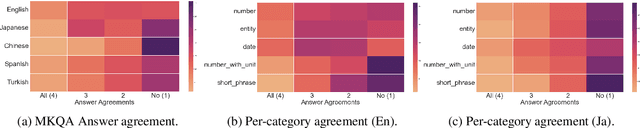
We present the results of the Workshop on Multilingual Information Access (MIA) 2022 Shared Task, evaluating cross-lingual open-retrieval question answering (QA) systems in 16 typologically diverse languages. In this task, we adapted two large-scale cross-lingual open-retrieval QA datasets in 14 typologically diverse languages, and newly annotated open-retrieval QA data in 2 underrepresented languages: Tagalog and Tamil. Four teams submitted their systems. The best system leveraging iteratively mined diverse negative examples and larger pretrained models achieves 32.2 F1, outperforming our baseline by 4.5 points. The second best system uses entity-aware contextualized representations for document retrieval, and achieves significant improvements in Tamil (20.8 F1), whereas most of the other systems yield nearly zero scores.
EASE: Entity-Aware Contrastive Learning of Sentence Embedding
May 09, 2022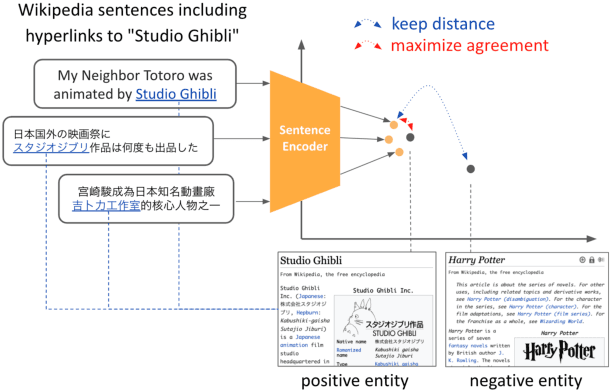
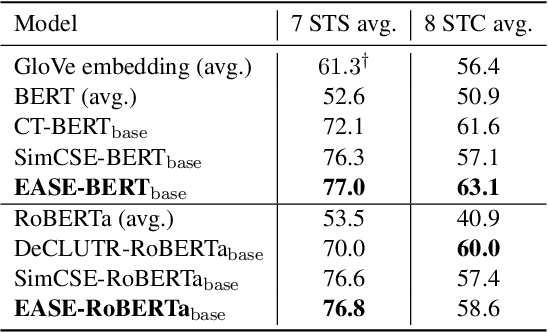

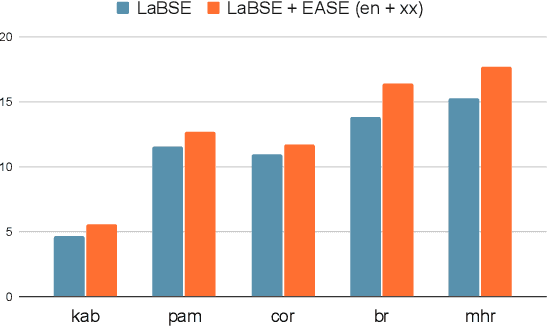
We present EASE, a novel method for learning sentence embeddings via contrastive learning between sentences and their related entities. The advantage of using entity supervision is twofold: (1) entities have been shown to be a strong indicator of text semantics and thus should provide rich training signals for sentence embeddings; (2) entities are defined independently of languages and thus offer useful cross-lingual alignment supervision. We evaluate EASE against other unsupervised models both in monolingual and multilingual settings. We show that EASE exhibits competitive or better performance in English semantic textual similarity (STS) and short text clustering (STC) tasks and it significantly outperforms baseline methods in multilingual settings on a variety of tasks. Our source code, pre-trained models, and newly constructed multilingual STC dataset are available at https://github.com/studio-ousia/ease.
mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models
Oct 15, 2021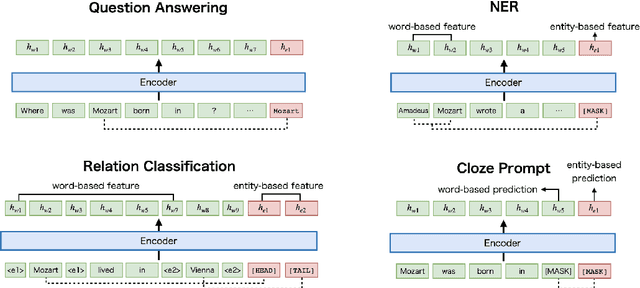
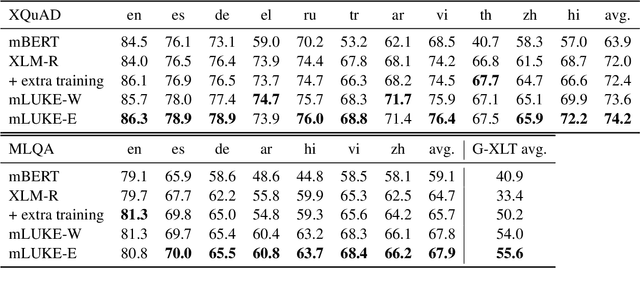

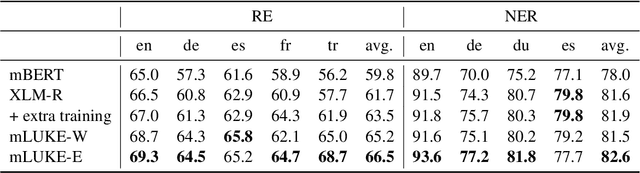
Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages with entity representations and show the model consistently outperforms word-based pretrained models in various cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual knowledge more likely than using only word representations.
A Multilingual Bag-of-Entities Model for Zero-Shot Cross-Lingual Text Classification
Oct 15, 2021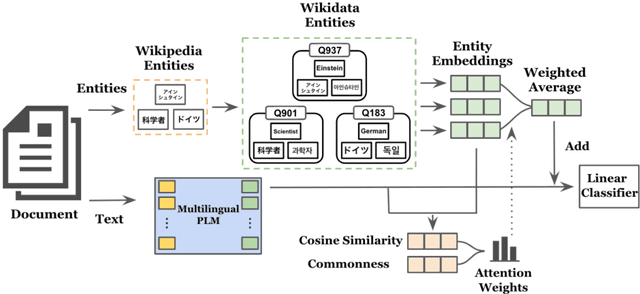
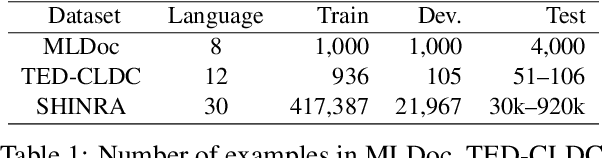
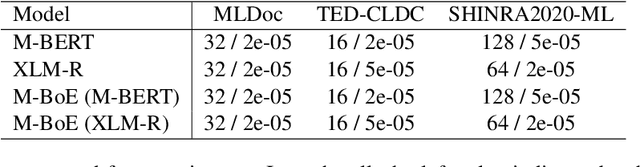
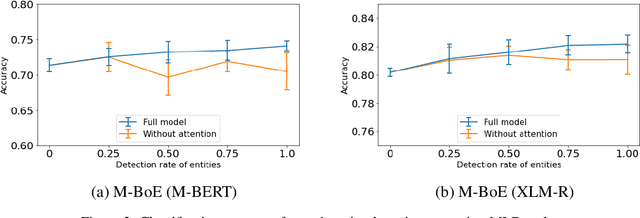
We present a multilingual bag-of-entities model that effectively boosts the performance of zero-shot cross-lingual text classification by extending a multilingual pre-trained language model (e.g., M-BERT). It leverages the multilingual nature of Wikidata: entities in multiple languages representing the same concept are defined with a unique identifier. This enables entities described in multiple languages to be represented using shared embeddings. A model trained on entity features in a resource-rich language can thus be directly applied to other languages. Our experimental results on cross-lingual topic classification (using the MLDoc and TED-CLDC datasets) and entity typing (using the SHINRA2020-ML dataset) show that the proposed model consistently outperforms state-of-the-art models.
Efficient Passage Retrieval with Hashing for Open-domain Question Answering
Jun 02, 2021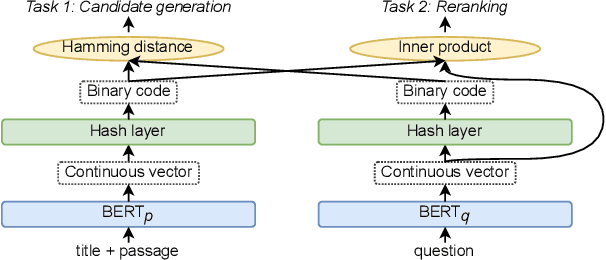
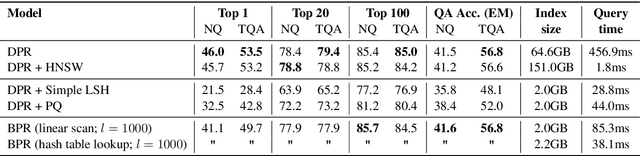
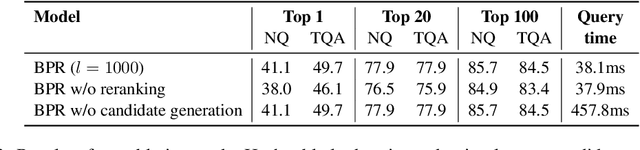

Most state-of-the-art open-domain question answering systems use a neural retrieval model to encode passages into continuous vectors and extract them from a knowledge source. However, such retrieval models often require large memory to run because of the massive size of their passage index. In this paper, we introduce Binary Passage Retriever (BPR), a memory-efficient neural retrieval model that integrates a learning-to-hash technique into the state-of-the-art Dense Passage Retriever (DPR) to represent the passage index using compact binary codes rather than continuous vectors. BPR is trained with a multi-task objective over two tasks: efficient candidate generation based on binary codes and accurate reranking based on continuous vectors. Compared with DPR, BPR substantially reduces the memory cost from 65GB to 2GB without a loss of accuracy on two standard open-domain question answering benchmarks: Natural Questions and TriviaQA. Our code and trained models are available at https://github.com/studio-ousia/bpr.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021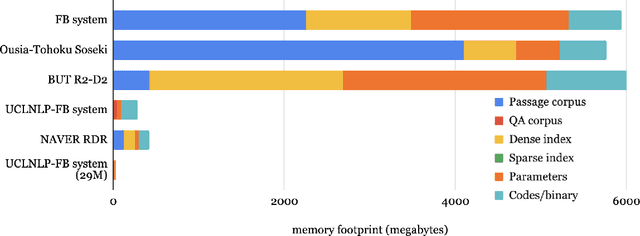
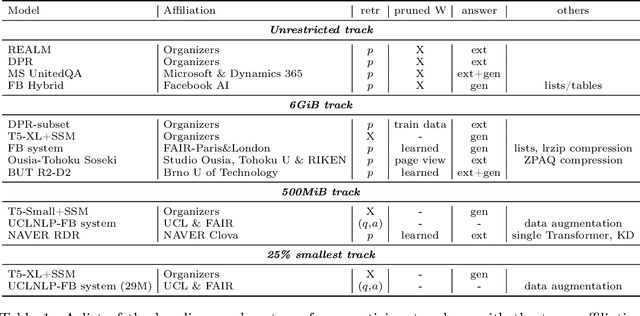
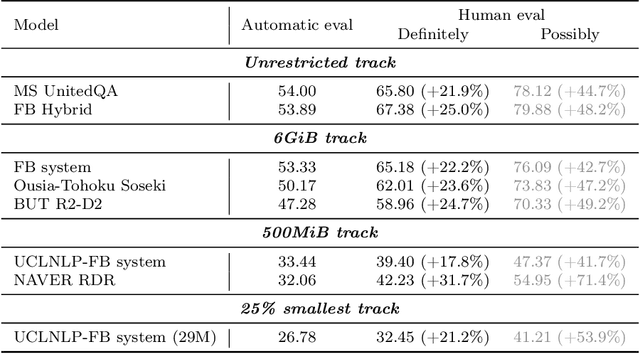
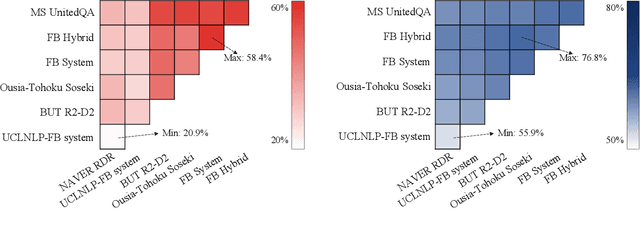
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
Oct 02, 2020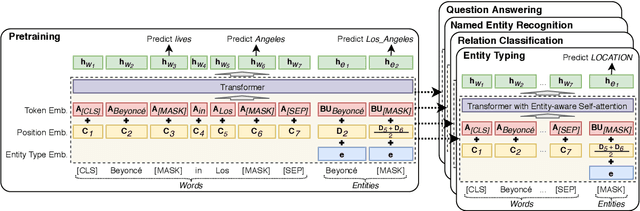
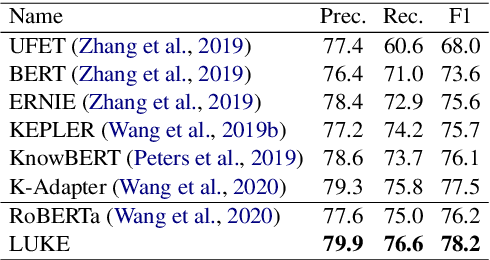
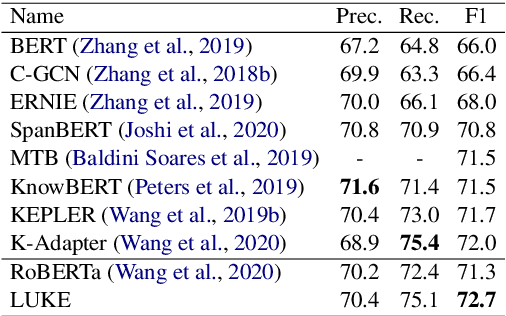
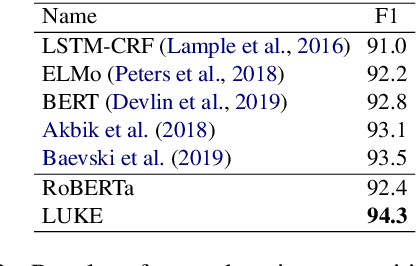
Entity representations are useful in natural language tasks involving entities. In this paper, we propose new pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed model treats words and entities in a given text as independent tokens, and outputs contextualized representations of them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification), CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question answering). Our source code and pretrained representations are available at https://github.com/studio-ousia/luke.